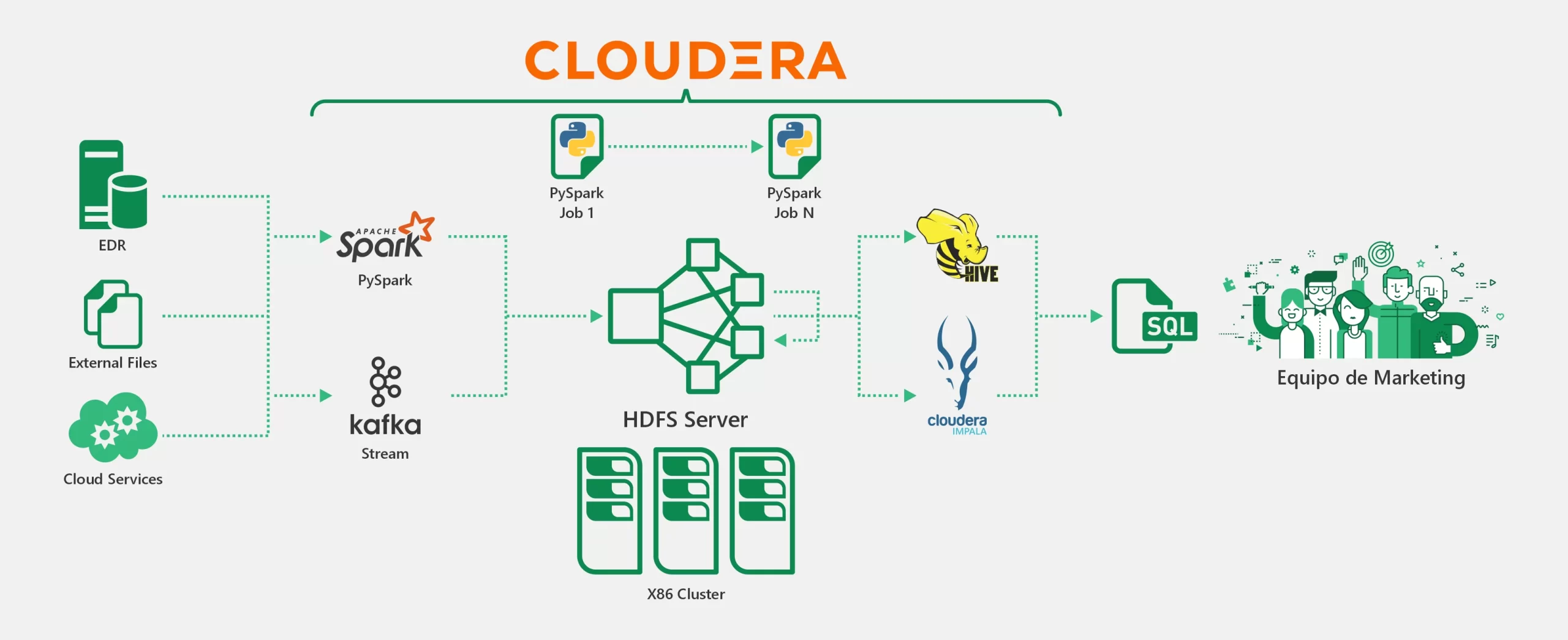
SOLUCIÓN:
La solución está basada en el framework de Cloudera. La ingesta de datos se manejaba mediante Spark (PySpark) y Kafka hacia un HDFS donde se tiene Hive e Impala como interfaces de consulta.